The Inherent Logic of AI Applications in Finance
01 AI and Banking Information Processing
(1) Observations and Issues
In the application of AI in banking information processing, there are three key observations. First, generative AI has expanded from large language models to multimodal models that can handle images, audio, and video. Currently, it is mainly used for document generation (such as meeting minutes, customer service scripts, loan due diligence reports, exit audit reports, and contract analysis), code generation, document verification, knowledge bases, and intelligent Q&A. However, due to hallucinations, large language models struggle to directly participate in customer-facing decisions and core business judgments. Second, interpretable AI combined with alternative data can efficiently and accurately assess borrowers’ willingness and ability to repay, and it has been widely applied in bank credit assessments. Third, under the capital regulation requirements, the internal rating method (which primarily assesses the probability of borrower default, PD) still mainly relies on traditional small models like linear regression and logistic regression.
A December 2024 research report from the Bank for International Settlements (BIS) surveyed the global banking sector’s use of AI, as shown in Table 1:
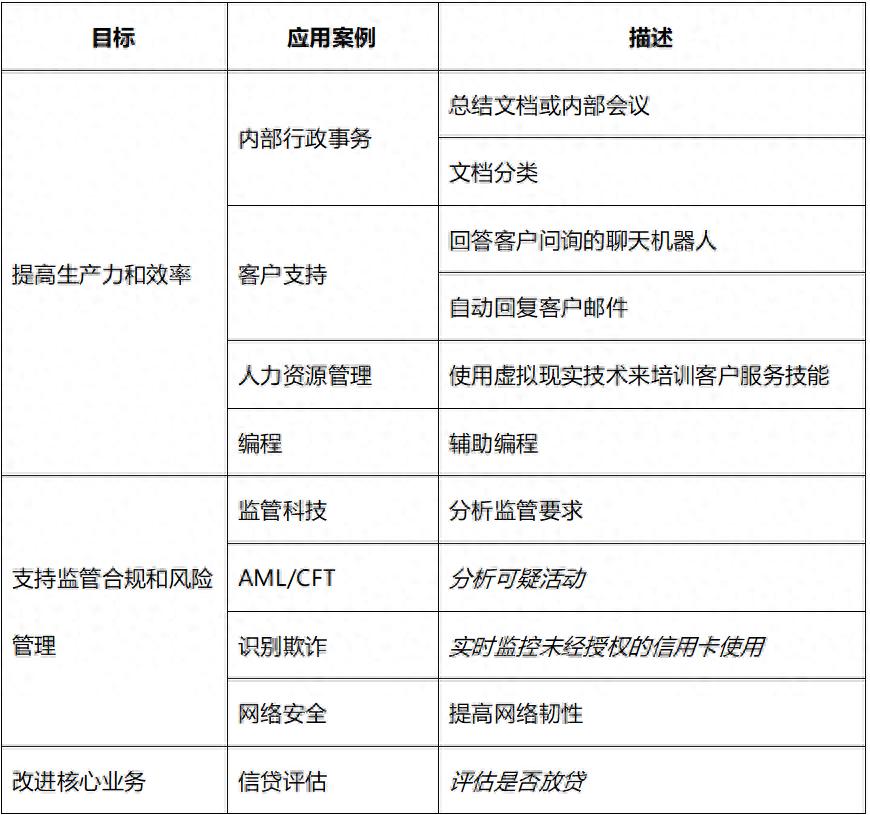
In Table 1, except for anti-money laundering (AML)/counter-terrorism financing (CFT) applications such as “analyzing suspicious activities,” “real-time monitoring of unauthorized credit card usage,” and “assessing whether to lend,” which mainly belong to interpretable AI, other application scenarios are primarily generative AI.
This raises three questions for discussion. First, what roles will small models, interpretable AI, and generative AI play in banking information processing? Second, what impact does this have on banks’ model risk management? Third, how does this affect banks’ credit assessment and approval processes?
It should be noted that while interpretable AI and generative AI are discussed in parallel, they are not in opposition. First, both types of AI are based on artificial neural networks, but they differ in architecture. Currently, generative AI mainly uses the Transformer architecture based on attention mechanisms, while interpretable AI employs a more diverse range of neural network architectures. Second, despite differences in the types of data analyzed, both types of AI use neural networks to estimate data probability distributions. Interpretable AI is mainly applied to classification problems (such as classifying borrowers as likely to default or assigning different credit ratings) and predicting the probability of belonging to a certain category. The core of generative AI is to predict the next token probabilistically, providing a probability distribution for the next token in the vocabulary before making a prediction. In other words, generative AI inherently includes a classification problem regarding the next token (interpretable AI).
(2) Lending Technology and Information Processing
There is information asymmetry between banks and borrowers, and the core goal of banking information processing is to assess borrowers’ willingness and ability to repay. Although the information processed by banks can vary greatly in specific forms, it can mainly be categorized into two types. First, hard information, which generally exists in numerical form, is quantitative, structured, and devoid of subjective judgment, opinions, or observations. Second, soft information, which generally exists in textual form, is qualitative, unstructured, and inseparable from subjective judgment, opinions, and observations, requiring contextual understanding. Corresponding to these two types of information, banks primarily use two types of lending techniques. First, transaction-based lending uses hard information such as corporate financial statements and credit scores. Second, relationship-based lending uses soft information accumulated through long-term, multi-channel interactions with enterprises, which cannot be obtained from corporate financial statements or public channels. From the perspective of this analysis, the following two relationships can be approximated:
Hard Information ≈ Structured Data → Transaction-Based Lending
Soft Information ≈ Unstructured Data → Relationship-Based Lending
For structured data, there are very mature analytical methods, generally divided into four steps. First, it is assumed that there is a data generation process behind the structured data that needs to be estimated. This process can be based on causal relationships provided by theoretical research (corresponding to structured models) or on statistical correlations between variables (corresponding to simplified models). The data generation process includes a series of unknown parameters to be estimated, as well as error terms or random disturbances to account for observational errors and missing variables. Second, parameters are estimated using sample data. Empirical economic research generally conducts hypothesis testing based on parameter estimates, but in practice, prediction is more important. Third, the estimated model is used to make predictions outside the sample. Fourth, the prediction effectiveness is evaluated. If the prediction effectiveness is unsatisfactory, the model settings or parameter settings can be adjusted (i.e., model selection or tuning).
In the banking sector, representative applications of structured data analysis include: first, identity verification, recognizing user identity based on biometric features such as facial recognition, fingerprints, iris, and voice; second, credit assessment, evaluating borrowers’ creditworthiness (likelihood of default and degree of default risk); third, anomaly transaction detection, identifying abnormal transactions and fraud.
For a long time, non-structured data represented by text, images, audio, and video was believed to be generated only by the human brain and could not be generated by algorithms. The development of large models has proven that the inherent patterns of non-structured data are more abundant than previously thought. First, non-structured data can be transformed into word vectors (essentially points in a low-dimensional space) through embedding or tokenization, allowing it to be processed by artificial neural networks. Representative methods in this area include Word2Vec, GloVe, and FastText. Second, large models represented by ChatGPT use the Transformer architecture based on attention mechanisms to effectively identify implicit patterns and structures in non-structured data through statistical learning. Subsequently, large models predict the reasonable continuation of non-structured data probabilistically (i.e., the “next token”), manifested as responses to prompts.
(3) Model Interpretability, Prediction Errors, and Model Risk Management
Regardless of whether dealing with structured or non-structured data, banks’ processing methods are essentially data modeling. The scenarios in which banks use which models can all be incorporated into a model risk management framework, depending on two key characteristics of the models—interpretability and prediction error.
Model interpretability is divided into two dimensions. First, internal interpretability aims to explain how the model operates, answering the “How” questions. Second, external interpretability aims to explain why the model produces a certain result, answering the “Why” questions. Generally, the more complex the data generation process and the more unknown parameters there are (“the larger the model”), the lower the model’s interpretability. Therefore, both interpretable AI and generative AI based on artificial neural networks are inherently less interpretable than traditional small models like linear regression and logistic regression, exhibiting “black box” characteristics.
The prediction error of models dealing with structured data is easily measurable. If the predicted variable is continuous (such as economic growth rate and corporate profit), the prediction error can be measured using mean squared error (MSE). If the predicted variable is discrete (such as whether to default or which credit rating to belong to), prediction errors can be measured using two types of errors (“false negatives,” “false positives”) and the area under the ROC curve (AUC).
For large models processing non-structured data, hallucinations correspond to prediction errors. Since large models predict the next token probabilistically, any generated token deviating from the true situation is part of the inherent nature of the task. This is not a “bug” that can be fixed by improving the architecture of artificial neural networks or using more training data and computational power; rather, it is an intrinsic feature of large models. Using large models means accepting the risk of hallucinations. In practice, this risk is generally mitigated by combining retrieval-augmented generation (RAG) techniques and knowledge graphs, which essentially uses other information processing methods in scenarios where tolerance for hallucination risk is low, rather than fixing the hallucination issue of large models. It should also be noted that understanding non-structured data, including this article, involves subjective factors, making it more challenging to assess the effectiveness of text generation compared to evaluating the prediction effectiveness of structured data. Techniques for aligning large models, such as supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF), address this issue.
From a model risk management perspective, the presence of interpretability issues or prediction errors does not mean that the model is unusable; rather, it requires management based on the application scenario and risk tolerance. Different banks and different application scenarios may have varying tolerances for model risk. For example, generally, an AUC of 0.65 for internal credit assessment models is acceptable. Model risk management can also apply a “three lines of defense” management framework similar to credit risk, market risk, and liquidity risk.
Both interpretable AI and generative AI can be incorporated into mainstream analytical frameworks for risk management. From a micro-prudential regulatory perspective, the risks posed by AI mainly manifest in the following aspects. First, credit risk: underestimating default probabilities or losses after default. Second, cybersecurity risk: increased connections with external service providers; increased IT connections between multiple systems; AI encountering “data poisoning” during model training. A recent high-profile incident involved Anthropic’s Claude Mythos being used to discover code vulnerabilities. Third, reputational risk: operational failures affecting public trust; unfair treatment of customers leading to negative public sentiment. Fourth, strategic risk: partnerships with other institutions causing banks to lose control over core functions. Fifth, legal risk: training data for AI models may infringe on rights; customer-facing AI tools may provide inaccurate or inappropriate responses. Sixth, data privacy risk: AI models may leak personal or sensitive information during training and use.
From a macro-prudential regulatory perspective, the risks posed by AI mainly manifest as: first, “herd” behavior, arising from different banks using the same foundational models and training data; second, market concentration and interconnection caused by third-party AI providers. So far, very few large banks have developed high-performing foundational models through pre-training, mainly relying on foundational models developed by leading AI companies and internet companies, and the trend of concentration among foundational models and related suppliers cannot be ignored.
Overall, different models should leverage their respective advantages based on application scenarios to achieve synergistic effects. There is no substitute relationship between small models, interpretable AI, and generative AI; rather, they are complementary. Due to hallucinations, large models cannot be directly used for bank customers but can serve as a “co-pilot” for bank employees, assisting in information processing and report generation. The output of large models can also serve as input for small models. Large models will significantly enhance banks’ efficiency and effectiveness in processing non-structured data.
(4) The Sequence of AI Penetration in the Banking Sector
Currently, generative AI is mainly used in internal auxiliary scenarios within banks. Although interpretable AI has shown good application results in bank credit assessments, regulatory agencies still prefer the stronger interpretability of small models. For example, in the Basel Capital Accord, the core tool for measuring risk capital is Value at Risk (VaR); the foundation for measuring credit risk in loan portfolios is the progressive single-factor risk model; and the mainstream tools for measuring default probabilities (PD) in internal rating methods are linear regression and logistic regression. Therefore, the penetration sequence of AI in the banking sector is illustrated in Figure 1.
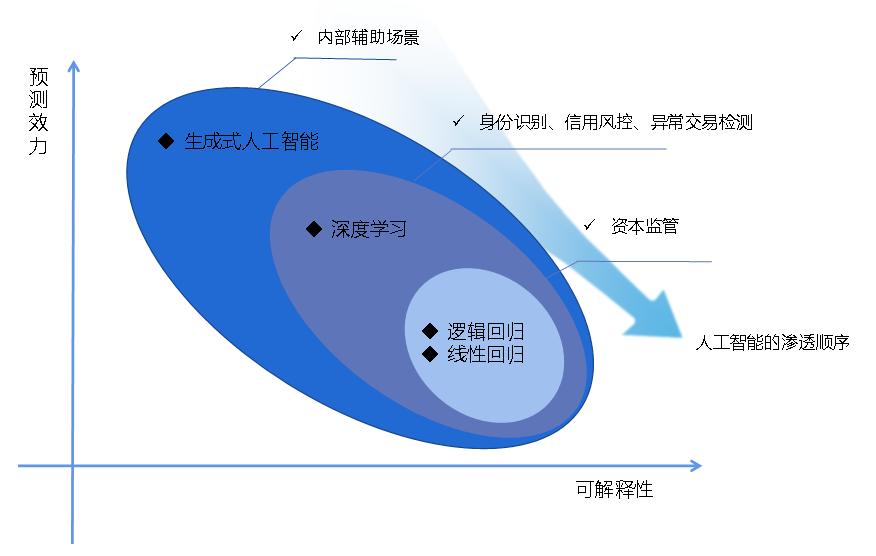
From Figure 1, it can be seen that: first, there is an inverse relationship between model interpretability and predictive effectiveness, with generative AI having the strongest predictive effectiveness but the lowest interpretability; second, the penetration sequence of AI in the banking sector gradually deepens from internal auxiliary scenarios to core scenarios represented by capital regulation.
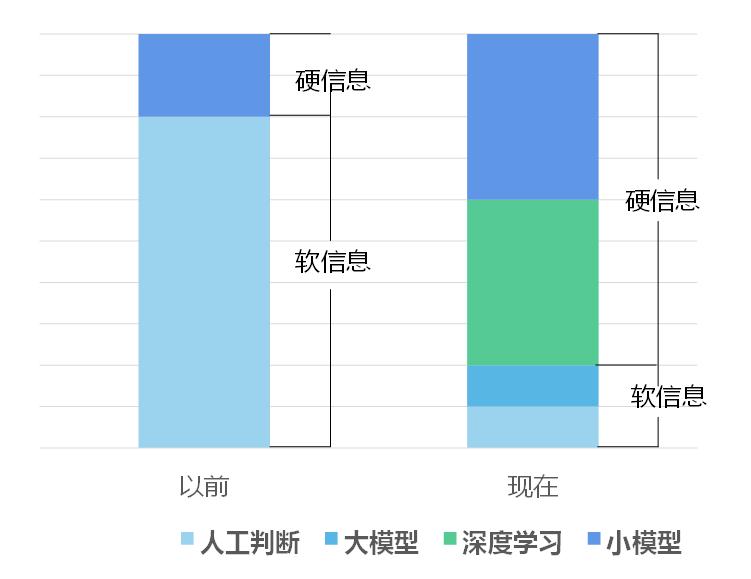
Figure 2 shows the impact of AI on banking lending technology. With the development of information and communication technology (ICT), an increasing amount of information is being collected and recorded digitally (the proportion of hard information is increasing), making it an object that can be analyzed by models. Large models have significantly improved banks’ ability to analyze non-structured data. Consequently, some relationship-based lending will transform into transaction-based lending, and banks’ credit approval authority can be appropriately centralized. This trend is already emerging in practice.
02 Three Levels of AI Applications in the Financial Sector and Their Impact
Based on financial information processing, AI has broad application prospects in the financial sector. On one hand, the characteristics of the financial industry are well-suited for AI; on the other hand, the evolution of AI from “tool → assistant → intelligent agent” will deepen its applications in finance. Under the combined force of these two aspects, the application of AI in finance will reflect three levels and will have profound impacts on the financial industry.
(1) Compatibility of the Financial Industry and AI
The compatibility of the financial industry with AI is mainly reflected in two aspects. First, industry characteristics match. First, the financial industry is information-intensive, with a large amount of work involving processing reports, announcements, contracts, regulatory documents, and other non-structured texts, which aligns with the core capabilities of large language models. Large models will enable non-structured data to enter the financial system more effectively, improving the efficiency of financial activities. Second, the financial industry is process-intensive, with clear steps in business processes and defined inputs and outputs, facilitating AI’s role from assisting individual steps to participating in complete processes, and many manual operations in the process can be replaced by automated tools. Finally, the financial industry is rule-intensive, providing clear operational boundaries for AI. The combination of “process-intensive + rule-intensive” allows AI to be deeply embedded in financial business processes, from processing information to processing funds. Second, pressures from cost efficiency, customer competition, compliance, and talent development drive financial institutions to deploy AI. Especially in China, the banking industry has a strong motivation to deploy AI against the backdrop of declining net interest margins.
The strongest foundational AI models are generally developed by leading AI companies and internet companies, but the financial industry has high data security requirements and cannot directly use public APIs. After several years of exploration, the financial industry has gradually converged on three data security solutions. First, the “firewall gateway” model: financial institutions build comprehensive AI platforms to connect with external models, and employee requests are routed through internal gateways, with data encrypted, desensitized, and permission-checked before being sent to external models. Second, hybrid cloud architecture: processing is layered based on data sensitivity, with the most sensitive data remaining in private clouds or local environments, moderately sensitive tasks processed through enterprise-level public clouds with encryption and isolation, and non-sensitive loads considering more open cloud environments. Third, complete local deployment: using open-source models running on the enterprise’s own infrastructure, with all data processing completed internally without relying on external APIs.
(2) Evolution of AI from “Tool → Assistant → Intelligent Agent”
The evolution of AI from “tool → assistant → intelligent agent” is not primarily about the replacement of technological generations (currently, mainstream large models are all based on the Transformer architecture, and no competitive alternative architecture has emerged), but rather about changes in human-machine relationships, reflected in the expansion of four boundaries. First, capability boundary: what can AI do at each stage, and what can it not do? Second, permission boundary: what systems and data is AI allowed to access and operate? Third, process boundary: the depth and breadth of AI’s embedding in business processes. Fourth, responsibility boundary: how is responsibility assigned in decisions and actions involving AI?
- Tool or “Co-pilot”
The core feature of this stage is “human initiates, leads, and reviews”; AI provides suggestions, supplements information, and accelerates output but does not take proactive actions, connect to other systems, or execute operations; each human-machine interaction is independent. Representative applications include chatbots, where large models primarily perform the basic function of “generating the next token probabilistically.”
- Assistant
The core feature of this stage is “humans assign tasks, AI collaborates continuously, and humans retain key judgment rights”; AI “knows” who the user is, what they are doing, and what has been discussed previously, enabling continuous follow-up, “remembering” past interactions, and “understanding” preferences, and it begins to be embedded in specific job workflows but does not act autonomously or directly operate the user’s computer system.
This stage benefits from retrieval-augmented generation (RAG) technology. The output of large models can be combined with results from search engines, knowledge graphs, and expert knowledge, alleviating the hallucination problem of large models and improving the accuracy and timeliness of output results.
AI “remembers” past interactions and continuously interacts with users based on the inclusion of past interaction records in prompts. However, this interaction does not change the weight settings of large models; the large model does not undergo true “learning.” If the large model is viewed as a function, with the weights of the large model as parameters of the function, then including past interaction records in prompts changes the function’s output by altering the function’s input; however, the parameters of the function remain unaffected, and the large model itself does not change. In other words, the “memory” about the user is reflected in the prompts, and the large model has no memory of the user.
- Intelligent Agent
The core feature of this stage is that AI can plan steps, call tools, connect computer systems, and adjust execution based on feedback; this does not equate to complete automation, but rather a more realistic form of bounded semi-automated execution, where AI operates autonomously under clear planning, permissions, and approval nodes, while key decisions still require human approval.
Currently, there are many exaggerated and inaccurate claims about intelligent agents in the media. Intelligent agents do not change the basic function of large models “generating the next token probabilistically”; they can repeatedly call large models but do not change the weights of large models. What intelligent agents change is the way large models are called and the interaction between large models and computer systems, with related innovations summarized as “context engineering.” First, the output of large models includes instructions for calling computer systems. Next, if users grant authorization or approval, these instructions will be executed on the user’s computer system, producing real effects, making it appear that large models are not just “talking without action.” Then, these real effects are incorporated into prompts as new input to call large models. This back-and-forth allows large models to execute complex tasks step by step under human instructions, authorizations, and approvals.
This stage also benefits from standardized connection protocols such as Model Context Protocol (MCP) and Agent-to-Agent (A2A) protocols, enabling mutual calls and collaboration among multiple intelligent agents.
The implementation of intelligent agents relies on several prerequisites. First, tool interfaces: intelligent agents need to connect to users’ computer systems through standardized interfaces. Second, permission layering: the scope of access and operations for intelligent agents must be strictly defined. Third, approval nodes: key steps involving fund transfers, modifications to customer information, or external communications must have human approval. Fourth, log tracking: every decision and action taken by intelligent agents must be fully recorded to support post-audit. Fifth, evaluation mechanisms: ongoing monitoring of the quality of intelligent agent outputs and compliance with behavior is required. Sixth, human fallback: there must be clear escalation and fallback pathways for intelligent agents when they encounter situations they cannot handle.
(3) Three Levels of AI Applications in the Financial Sector
- As a Tool Enhancing Individuals
First, back-office roles such as legal, compliance, customer service, code development, and document processing have a faster deployment speed for AI due to high frequency and standardization of tasks. Second, for knowledge-intensive front-office roles (such as investment research), AI will replace some repetitive labor, changing the speed of information acquisition and material organization in the workflow, but not altering the responsibility for decision-making. At this level, all business risks, compliance requirements, and final decision-making responsibilities remain entirely with human employees.
- As an Assistant Understanding Roles, Context, and Customers
First, as an employee-facing assistant. The assistant can continuously work around the employee’s role, follow up on customer relationships the employee is handling, and organize relevant materials before the employee’s next customer meeting. Second, as a customer-facing assistant. AI begins to participate in tasks such as checking bills, confirming transfers, and lightweight service processes. At this level, although core judgment rights remain with human employees, the responsibility boundaries begin to blur as AI provides personalized suggestions based on multidimensional data tracking.
- Intelligent Agents Begin to Participate in Complete Business Processes
AI takes over multi-step tasks within clear boundaries to free up human resources for handling unexpected events and key judgments. Currently, intelligent agents are mainly applicable in two types of scenarios. First, rule-driven process scenarios. For example, anti-money laundering, sanction compliance, KYC review, and compliance reporting, which have clear rules, standardized steps, and defined data sources. Second, mixed scenarios of “knowledge + process.” For example, data collection and preliminary analysis in investment research departments, financial report comparisons, market monitoring and early warning, and customer management task scheduling.
(4) Impact of AI on the Financial Sector
-
Impact on Business Models. First, customer service shifts from passive response to proactive management. For example, wealth management models evolve from standardized asset allocation tools to dynamic management models based on customer goals. Second, service entry points expand. Financial service entry is no longer limited to bank branches or mobile apps but begins to extend to conversational AI platforms. For instance, Mastercard and OpenAI collaborate to allow customers to complete payments during conversations with AI without switching to the bank interface. Finally, inter-agent payments are a recently popular area of interest.
-
Impact on Organizational Roles and Talent Structure. First, job impacts. Tasks that are rule-clear, step-splittable, and have standardized inputs and outputs, such as back-office operations, entry-level research, and compliance processing, are more easily automated. Tasks involving customer relationships, complex judgments, ethical decisions, and creative strategies are harder to replace. The overall trend is to “reshape roles” rather than simply “replace roles,” achieving transformation through natural attrition and internal repositioning. Second, responsibility shifts. Employee responsibilities shift from manually executing each step to task design, outcome review, and handling unexpected situations. Employees need to not only master the business itself but also judge which tasks can be delegated to AI and which nodes must revert to human handling.
-
Impact on Technical Architecture. Financial institutions are deploying AI on a large scale towards foundational infrastructure. The complexity of AI infrastructure projects is high and involves layers of computing (computing scheduling and optimization), data (unified knowledge base and data permission systems), models (selection, updating, and retirement governance of multiple models), and tools (providing standardized system connection interfaces for intelligent agents), making it a systemic engineering challenge. The evolution of AI from “tool → assistant → intelligent agent” also reflects the path of financial institutions moving from partial deployment to platform construction. The tool stage can tolerate localized pilots, the assistant stage requires role and context connectivity, and the intelligent agent stage requires reliable collaboration between systems. Therefore, AI is no longer just a project for the IT department but requires an independent organizational structure, dedicated budget, and executive-level governance oversight.
(5) Future Outlook
Benefiting from the enhancement of intelligent agent capabilities, AI is expected to evolve from a single model into a dispatching hub. This upgrade is reflected in the reconstruction of two dimensions: data retrieval and model computation. In the data processing dimension, intelligent agents with autonomous planning capabilities can gradually replace traditional architectures. Hallucinations cannot be fixed by improving architecture or increasing training data; rather, they are inherent features of large language models predicting the next token probabilistically. To control this risk, data intelligent agents will downgrade the output of large models from final conclusions to verifiable middleware. When addressing business scenarios, intelligent agents can convert user intentions into structured query statements or executable code. Whether the code runs successfully and whether the underlying database returns reasonable results can be subjected to deterministic verification. Even if hallucinations occur during the query generation phase, they will be intercepted by the system during execution failures, thus preventing erroneous information from directly entering core processes.
In the model computation dimension, the collaborative calling of large general models and traditional specialized small models will become a key path to meet stringent regulatory requirements. To address the low interpretability black box characteristics of large language models, this architecture can retract uncertainty to the tool calling layer. In scenarios requiring high interpretability, the core risk measurement logic will still be completed by traditional specialized small models. Large models will not participate in the final numerical estimation; they will only process the preceding non-structured data and generate calling instructions. This design fully leverages the complementary advantages of different models and shifts the audit trail from the complex parameter weights of artificial neural networks to a complete traceable chain from natural language instructions to code execution and then to traditional specialized small model outputs. Whether it is the precise capture of underlying information by data intelligent agents or the computational distribution of large models to small models, this path of constraining uncertainty through architectural design rather than a single model can effectively meet the requirements of financial industry model risk management. A core issue that needs further discussion in the future is how to match log tracking, evaluation mechanisms, and human fallback approval nodes when the risk nodes of the system migrate from text generation to code generation and tool calling.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.